Toro is a unikernel written in Freepascal that compiles within the user application and enables to build appliances that can be executed in any modern hypervisor or cloud provider. There are use cases that require that appliances boot faster, e.g., deploying microservices on demand, rebooting from a crash, etc. In these use cases, appliances must be created and initialized and this procedure must be fast enough to keep the quality of service. In this article, we present the work done to speed up the booting time of a Toro appliance. This article begins by explaining how Toro boots up and how we improved current mechanisms by using a multiboot kernel. Then, we present three approaches namely QEMU, NEMU and Firecraker that aim at optimizing some aspects of the Virtual Machine Monitor (VMM) to speed up the booting time of an appliance.
What do we call “booting time”?
We call booting time the time until KernelMain() is invoked. During that time, the following steps are involved:
1. The VMM is initialized, e.g., device model initialization, BIOS. This happens at the host side.
2. The bootloader starts to execute, e.g., CPUs are initialized, paging is enabled, kernel is loaded into memory.
3. The kernel starts to execute, e.g., KernelMain() is executed.
In this article, booting time takes into account the time just before point 3.
How does current bootloader work in Toro?
• enables long mode and paging
• wakes up all the cores
• loads the kernel into memory
• jumps to the kernel main.
The benefit of using a RAW image is that the bootloader is simple. It just reads continuous blocks from the disk and put them into memory. No filesystem is needed. Also, it enables to boot the image in most hypervisors without extra work. In addition, the RAW image can be converted to VMDK format to launch a VM in VirtualBox or HyperV. The main drawback of using a RAW image is its size is too big since it is the copy of the kernel in memory. This increases the time to load the kernel into memory. Typically, an image is 4MB and takes about 1.5s to boot up.
The multiboot approach
One way to improve the size of the binary thus reducing the booting time is to leverage on the multiboot specification to generate a multiboot kernel and then use an existing bootloader to boot it up. To do this, the binary must be compiled by following a specific linkage. The binary needs to have a multiboot header that allows the multiboot bootloader to find the different sections and load them into memory. The user application and the kernel are still compiled together but the result is a multiboot binary.
The following figure illustrates what happens when the parameter “-kernel” is passed to QEMU. The kernel binary has to have an extra section named MultibootHeader. That section is used by QEMU to get information during the booting time. For example, it gets the starting address of the bootloader. QEMU then loads the .text and .data sections into memory and jumps to the starting address of the bootloader. In the figure, MultibootLoader is actually in the .text but we split it for the sake of simplicity. When the bootloader starts to execute, the CPU is already in protect mode and paging is enabled. Since previous steps are already done when the bootloader starts to execute, the code of the bootloader can be simplified thus saving time during booting time. The bootloader just has to enable long mode and wake up the cores.

By using the multiboot approach, the kernel binary is reduced to 145kb and the booting time results in about 450ms so we have a factor of 33% of improvement. The main drawback of this approach is that we need a VMM that supports the loading of a multiboot kernel. Otherwise, we need a bootloader that supports multiboot specification like grub.
Playing with the Virtual Machine Monitor
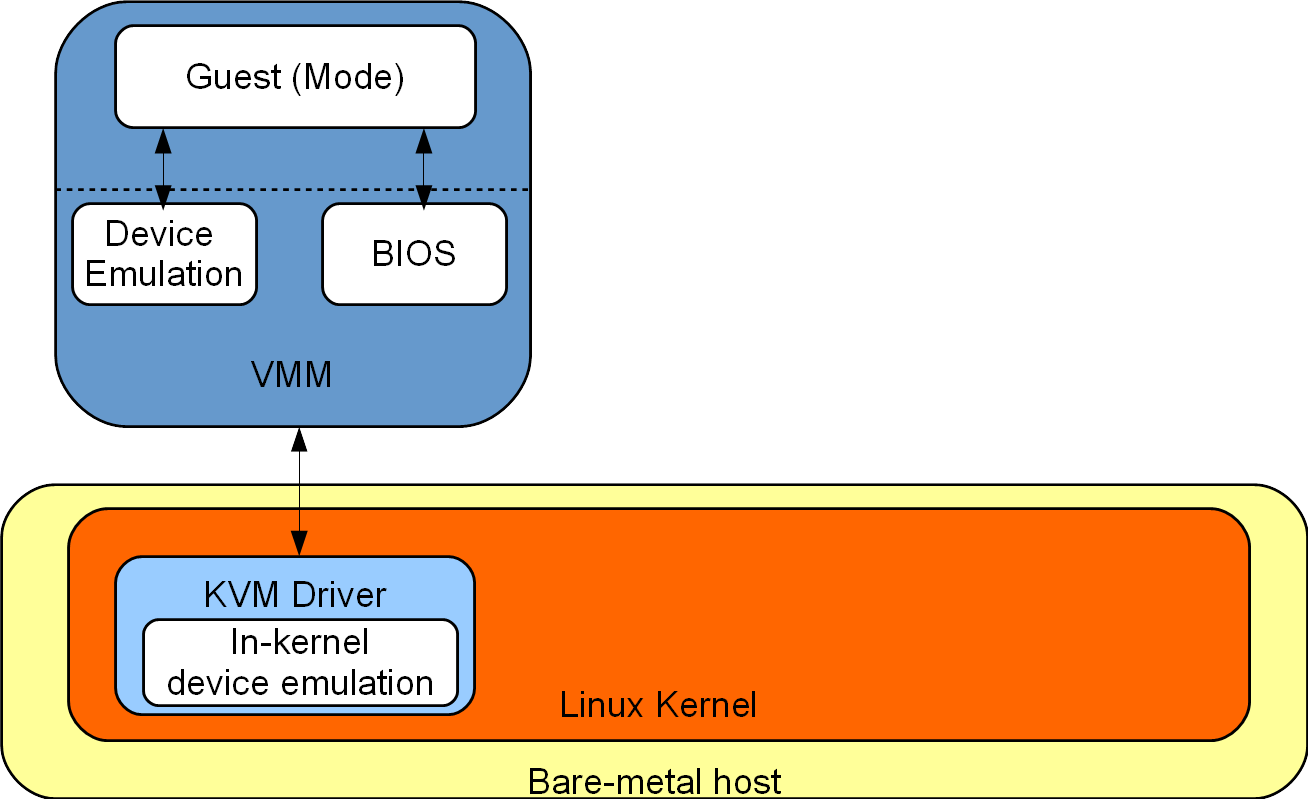
In this section, we present three approaches to improve the booting time by optimizing the VMM. Roughly speaking, these approaches simplify some aspect of the VMM, e.g., the loading of the kernel, the device model and/or the BIOS. The following figure illustrates the possible components that made a VMM. In this figure, the VMM is in charge of the Device Emulation and the BIOS. It communicates to the KVM driver, which can also provide in-kernel device emulation.
In the following, we roughly present each approach.
QBOOT
It is a minimal x86 firmware for QEMU to boot Linux (see http://github.com/bonzini/qboot). From authors, it is “a couple hardware initialization runtimes written mostly from scratch but with good help from SeaBIOS source code”.
NEMU
It is based on QEMU and only supports x86-64 and aarch64. It proposes a reduced device model by focusing on non-emulated devices to reduce the VMM’s footprint and the attack surface. It proposes a new machine type named “virt” which is thinner and only boots from EUFI.
Firecraker
It is a simple VMM implemented in Rust developed by Amazon Web Services to accelerate the speed and efficiency of services like AWS Lambda and AWS Fargate. The kernel binary must be a ELF64. When kernel starts to execute, the CPU is already in long mode and page tables are set in the Linux way. This simplifies a lot the bootloader.
To evaluate these approaches, we measure the time it takes the kernel to start to execute, i.e., the time since the VM is launched until KernelMain() is invoked. To know more about this work, you can check the issue #276 at GitHub. By using QBOOT in QEMU, Toro takes 135 ms to boot up. In case of NEMU, it takes 95ms. In the case of Firecraker, Toro takes only 17ms to boot up. Note that a simple “echo ‘Hello World’” in the same machine takes about 2.62 ms to execute.
Conclusions
We presented different approaches to speed up the booting time of a Toro appliance. Booting time is important when we want to launch appliances on demand or if we want to reboot an appliance because it has crashed. In the case of Toro, we show that by using multiboot kernel the size of the binary can be reduced from 4MB to 150kb and the booting time from 1.5s to 0.5ms. From there, improvements can be achieved by optimizing the VMM. Such improvements works on differents components of the VMM like the device model or the BIOS. For example, by using Firecraker, we are able to boot toro in 17ms.